Whether or not the provenance or even the veracity of the writing is questionable, this is something to think about, both for investors and for purveyors.
From Simon Willison's Weblog, May 4:
SemiAnalysis published something of a bombshell leaked document this morning: Google “We Have No Moat, And Neither Does OpenAI”.
The source of the document is vague:
The text below is a very recent leaked document, which was shared by an anonymous individual on a public Discord server who has granted permission for its republication. It originates from a researcher within Google.
Having read through it, it looks real to me—and even if it isn’t, I think the analysis within stands alone. It’s the most interesting piece of writing I’ve seen about LLMs in a while.
It’s absolutely worth reading the whole thing—it’s full of quotable lines—but I’ll highlight some of the most interesting parts here.
The premise of the paper is that while OpenAI and Google continue to race to build the most powerful language models, their efforts are rapidly being eclipsed by the work happening in the open source community.
While our models still hold a slight edge in terms of quality, the gap is closing astonishingly quickly. Open-source models are faster, more customizable, more private, and pound-for-pound more capable. They are doing things with $100 and 13B params that we struggle with at $10M and 540B. And they are doing so in weeks, not months.
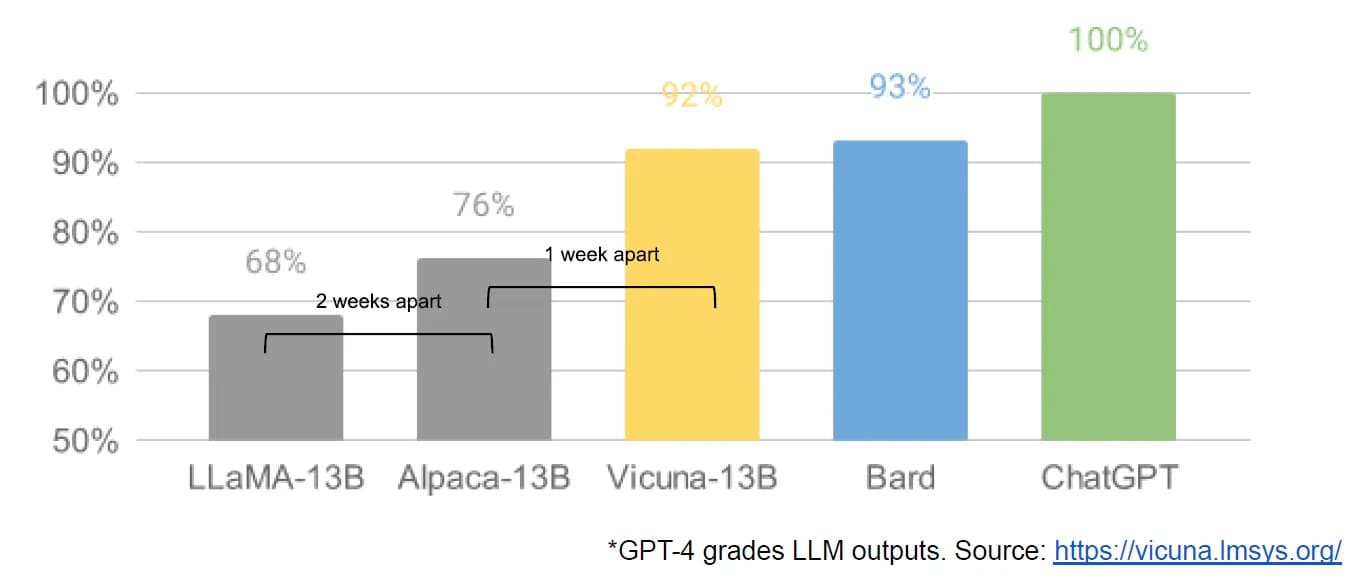
This chart is adapted from one in the Vicuna 13-B announcement—the author added the “2 weeks apart” and “1 week apart” labels illustrating how quickly LLaMA Vicuna and Alpaca followed LLaMA.
They go on to explain quite how much innovation happened in the open source community following the release of Meta’s LLaMA model in March:
A tremendous outpouring of innovation followed, with just days between major developments (see The Timeline for the full breakdown). Here we are, barely a month later, and there are variants with instruction tuning, quantization, quality improvements, human evals, multimodality, RLHF, etc. etc. many of which build on each other.
Most importantly, they have solved the scaling problem to the extent that anyone can tinker. Many of the new ideas are from ordinary people. The barrier to entry for training and experimentation has dropped from the total output of a major research organization to one person, an evening, and a beefy laptop.
Why We Could Have Seen It Coming...
....MUCH MORE
Previously from Simon Willison's Weblog: