From The Ideas Letter, April 16:
AI doesn’t really “think.” Rather, it remembers how we thought together. And we’re about to stop giving it anything worth remembering.
We are on the verge of the age of human redundancy. In 2023, IBM’s chief executive told Bloomberg that soon some 7,800 roles might be replaced by AI. The following year, Duolingo cut a tenth of its contractor workforce; it needed to free up desks for AI. Atlassian followed. Klarna announced that its AI assistant was performing work equivalent to 700 customer-service employees and that reducing the size of its workforce to under 2000 is now its North Star. And Jack Dorsey has been forthright about wanting to hold Block’s headcount flat while AI shoulders the growth.
The trajectory has a compelling internal logic. Routine cognitive work gets automated; junior roles thin out; productivity gains compound year on year. For boards reviewing cost structures, it is the cleanest investment proposition since the internal combustion engine retired the horse, topped up with a kind of moral momentum. Hesitate, the thinking goes, and fall behind.
But the research results of a team in the UK should give us pause. In the spring of 2024, they asked around 300 writers to produce short fiction. Some were aided by GPT-4 and others worked alone. Which stories, the researchers wanted to know, would be more creative? On average, the writers with AI help produced stories that independent judges rated as more creative than those written without it.
So far, so on message: a familiar story about the inevitable takeover by intelligent machines. But when the researchers examined the full body of stories rather than individual ones, the picture became murky. The AI-assisted stories were more similar to each other. Each writer had been individually elevated; collectively, they had converged. Anil R Doshi and Oliver Hauser, who published the study in Science Advances, reached for a phrase from ecology to explain this: a tragedy of the commons.
Hold that result in mind: individual gain, collective loss. It describes something far more consequential than a writing experiment—it describes the hidden logic of our entire relationship with artificial intelligence. And it suggests that the most successful organizations of the coming decade will be the ones that do something profoundly counterintuitive: instead of using AI to eliminate human interaction by firing droves of workers, they will use it to create more human interaction. IBM has reversed course on its earlier human redundancy fantasies. I bet more will in due course.
I.
Suppose you could travel to Egypt in 3000 BC and copy, in flawless hieroglyphics, the contents of every temple library, every architectural plan, every priestly manual, every commercial ledger. Then suppose you travelled to Mesopotamia and did the same in cuneiform. Consolidate everything you could find in the languages of that era, and then proceed to train a large language model on it. Full transformer architecture, self-attention, the whole enchilada.
The result would be a system capable of a certain kind of intelligence. It could predict floods from astronomical cycles. It could draft administrative correspondence. It could generate plausible religious commentary. But it would have no capacity for what the Greeks would later call the syllogism. It would carry no trace of Roman legal abstraction, and have no conception of the empirical method that wouldn’t emerge for another four millennia.
Now, let’s extend the experiment. Train a new model on the written output of 300 BC Athens: Aristotle, Euclid, Hippocrates, the commercial records of Mediterranean trade, etc. Another on 300 AD Rome, another on 1000 AD Baghdad, another on 1500 AD Florence, and finally one on the full internet-scale text production of the modern world.
Each model in this chain would be qualitatively smarter than the last. But it wouldn’t be smarter because you changed the architecture of the underlying technology (you didn’t). The reason would be that the civilization feeding the tech had changed. The 300 BC model would demonstrate logical inference that its Egyptian predecessor couldn’t approach. The 1500 AD model would handle probability and navigational calculation. And the 2025 model would exhibit the argumentative density, cross-domain reasoning, and multi-perspectival sophistication that characterize today’s frontier systems.
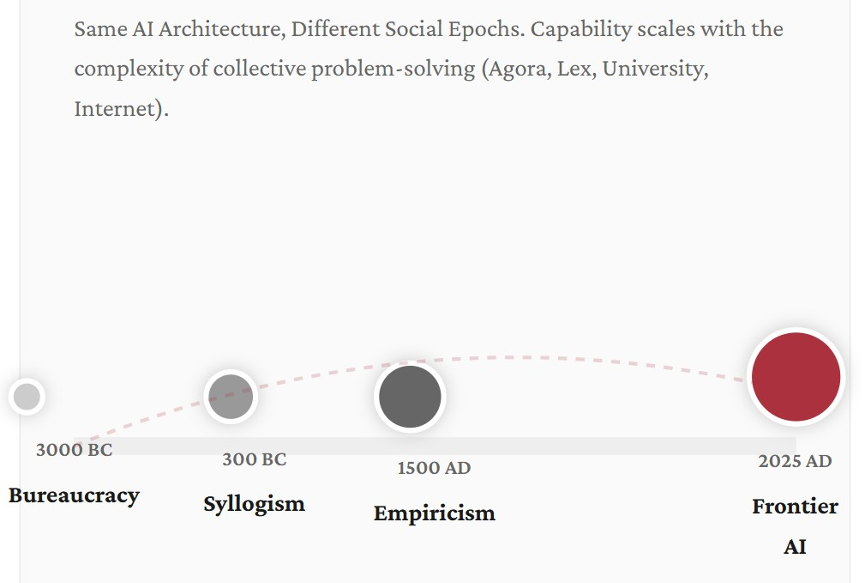
Figure 1. Civilizational substrates of intelligence
What the chain reveals is a dependency the AI industry has largely declined to examine. The underlying intelligence of a large language model isn’t a function of its architecture, its parameter count, or the volume of compute thrown at its training. It is not even about the training data. It is a function of the social complexity of the civilization whose language it digested.
Each epoch advanced the cognitive frontier through something far richer and more complex than the isolated genius of an individual guru or machine. It did so through new forms of collective problem-solving. Think new institutions (the Greek agora, the Roman lex, the medieval university, the scientific society, the modern corporation, and the social internet) that demanded and rewarded ever more sophisticated uses of language.
The cognitive anthropologist Edwin Hutchins studied how Navy navigation teams actually think. In his 1995 book Cognition in the Wild, he wrote something that reads today like an accidental prophecy. The physical symbol system, he observed, is “a model of the operation of the sociocultural system from which the human actor has been removed.”
That is, with eerie precision, a description of what a large language model (LLM) really is, stripped of all the unapproachable jargon and mathematical wizardry. An LLM like ChatGPT is a model of human social reasoning with the human wrangled out. And the question nobody in Silicon Valley is asking with sufficient urgency is: What happens to the model when the social reasoning that produced its training data begins to thin?
II.
In 2024, Ilia Shumailov and colleagues published a paper in Nature with a straight-talking title: AI models collapse when trained on recursively generated data. They demonstrated, with alarming mathematical precision, that language models trained on text generated by other language models start to degenerate partly because the distribution of the output narrows over successive generations. Minority viewpoints, rare knowledge, unusual formulations, and edge-case perspectives gradually vanish. The model converges on a kind of statistical average—fluent, plausible, and hollow. The tails of the distribution disappear first.
Consider what those tails represent. They are the traces of intellectual disagreement, of minority expertise, of Cassandra warnings, of institutional friction, and of the awkward and valuable fact that different people know different things and express them differently. They are, in other words, the signature of social complexity. Model collapse is social mind compression presented as a technical phenomenon.
Around the same time, the AI researcher Andrew Peterson analyzed what he called “knowledge collapse”: the harmful effect on public knowledge due to widespread reliance on AI-generated content. Even with a modest discount on AI-sourced information, public beliefs deviated 2.3 times further from ground truth. When people and organizations rely on AI summaries rather than engaging with primary sources, the diversity of available perspectives narrows.
Similarly, there is a variant of the Dunning Krueger effect, I suggest, that is found in those conversing with service chatbots that spare them the social bruises of hard conversations. When people choose to “ask Grok” to settle messy debates on Twitter/X, they are spreading this syndrome of overconfidence in one’s understanding of complex issues. It is easier to inflate your knowledge and understanding when you don’t have to deal with the social-regulatory feedback of ego-bruising disagreement. Blind spots grow bigger when one is cocooned in a machine-harem of pampering bots. What emerges over time is subtler than the militant ignorance of pre-AI social media. It is a confident, fluent, and remarkably homogeneous form of shallow knowing.
Anthropic, the maker of Claude, another LLM platform, has research results showing that in only 8.7% of user interactions with its platform do users pause to double-check what the bots spew out. That number reinforces something bigger than mere cognitive offloading and delegation. It enables systemic overconfidence which in turn diminishes curiosity, exploration, and knowledge-frontier defiance.
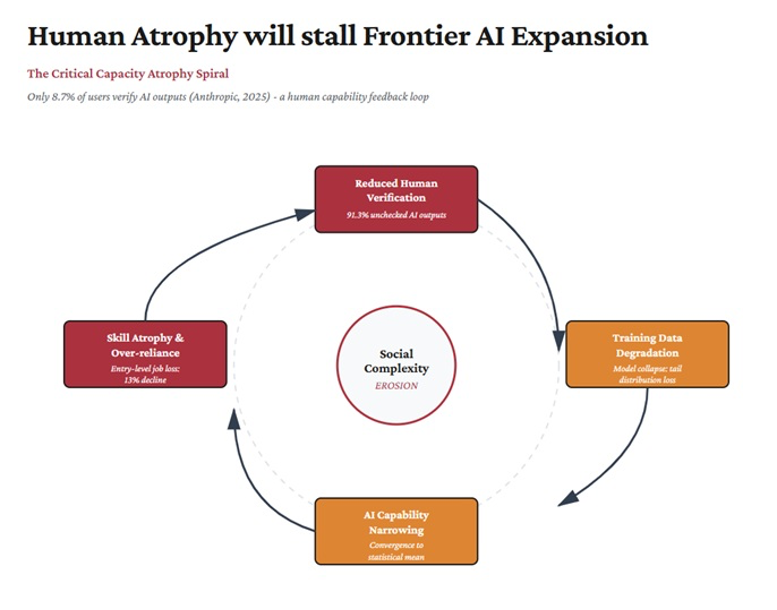
Figure 2. Cognitive overloading, overconfidence, underexploration & frontier AI regression
Meanwhile, a team at Epoch AI estimated that the total stock of quality-adjusted human-generated text available for training is roughly 300 trillion tokens, projected to be exhausted between 2026 and 2032. This is typically framed as a resource depletion problem as though we’re running out of data the way we might run out of water. But that framing misses the deeper point. The reservoir is not just being drained—the springs feeding it are starting to dry up....
....MUCH MORE