Wide Horizons: NVIDIA Keynote Points Way to Further AI Advances Chief Scientist Bill Dally described research poised to take machine learning to the next level
Dramatic gains in hardware performance have spawned generative AI,
and a rich pipeline of ideas for future speedups that will drive
machine learning to new heights, Bill Dally, NVIDIA’s chief scientist
and senior vice president of research, said today in a keynote.
Dally described a basket of techniques in the works — some already
showing impressive results — in a talk at Hot Chips, an annual event for
processor and systems architects.
“The progress in AI has been enormous, it’s been enabled by hardware
and it’s still gated by deep learning hardware,” said Dally, one of the
world’s foremost computer scientists and former chair of Stanford
University’s computer science department.
He showed, for example, how ChatGPT, the large language model (LLM)
used by millions, could suggest an outline for his talk. Such
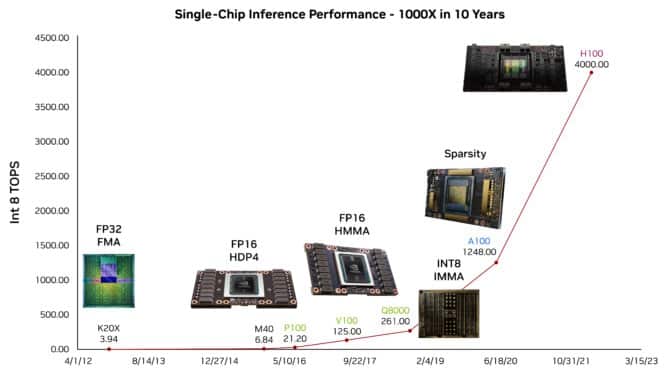
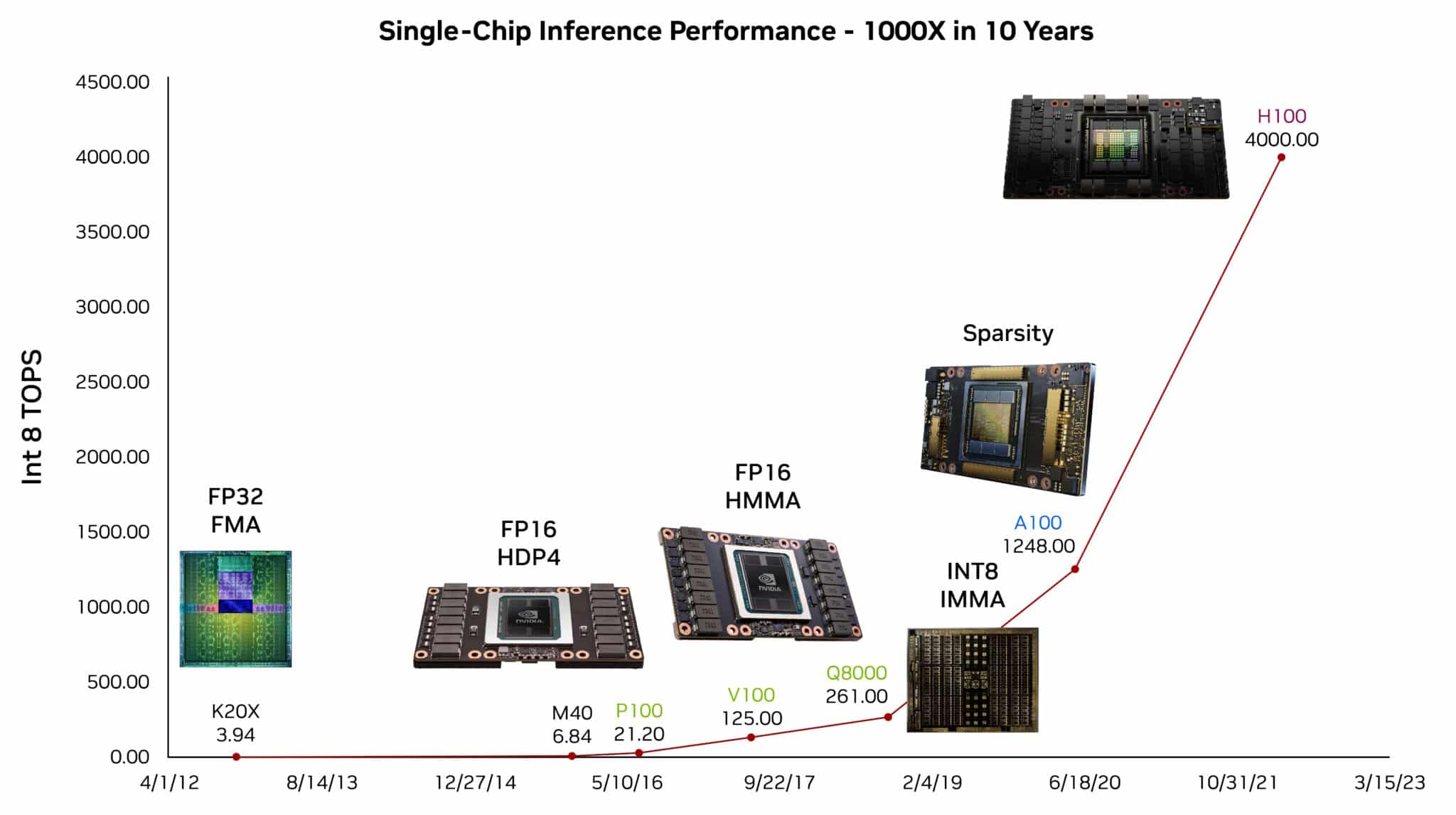
capabilities owe their prescience in large part to gains from GPUs in AI
inference performance over the last decade, he said.
Gains
in single-GPU performance are just part of a larger story that includes
million-x advances in scaling to data-center-sized supercomputers.
Research Delivers 100 TOPS/Watt
Researchers are readying the next wave of advances. Dally described a test chip that demonstrated nearly 100 tera operations per watt on an LLM.
The experiment showed an energy-efficient way to further accelerate the transformer models used in generative AI. It applied four-bit arithmetic, one of several simplified numeric approaches that promise future gains.
Looking further out, Dally discussed ways to speed calculations and
save energy using logarithmic math, an approach NVIDIA detailed in a
2021 patent.
Tailoring Hardware for AI He explored a half dozen other techniques for tailoring hardware to specific AI tasks, often by defining new data types or operations.
Dally described ways to simplify neural networks, pruning synapses
and neurons in an approach called structural sparsity, first adopted in NVIDIA A100 Tensor Core GPUs.
“We’re not done with sparsity,” he said. “We need to do something
with activations and can have greater sparsity in weights as well.”
Researchers need to design hardware and software in tandem, making
careful decisions on where to spend precious energy, he said. Memory and
communications circuits, for instance, need to minimize data movements.
“It’s a fun time to be a computer engineer because we’re enabling
this huge revolution in AI, and we haven’t even fully realized yet how
big a revolution it will be,” Dally said....