Their chip development/reverse engineering/R&D is coming along and I get the same feeling I did when the Chinese developed the Tianhe-2 in 2016 and we posted:
Milestone: China Builds The (NEW) World's Fastest Supercomuter Using Only Chinese Components (and other news) INTC; NVDA; IBM
But they still seem to be having a slow go of it in the building-a-chip-industry sense of what's what. However....
This MT-3000 processor could be the breakthrough/breakout.
From The Next Platform, February 9::
The Mystery Of Tianhe-3, The World’s Fastest Supercomputer, Solved?
We don’t like a mystery and we particularly don’t like it when what is very likely the most powerful supercomputer in the world – at this time anyway – is veiled in secrecy. But that is what the Tianhe-3 supercomputer built for the National Supercomputer Center in Guangzhou, China has been. Everyone has been trying to suss out what this system might look like. And the usual suspects here in the United States who would normally know, don’t.
So we are going to take a stab at figuring out what Tianhe-3 might look like. Just like we did for the “Oceanlight” system installed at the National Supercomputer Center in Wuxi, China before some details of the machine were disclosed thanks to the Gordon Bell Prizes that this particular beast has won.
Both the Oceanlight system and the Tianhe-3 machine, which very likely has the nickname “Xingyi” based on recent reports coming out of the Middle Kingdom, are too important to ignore. And we need to not only understand these two machines ahead of the formal disclosure of the capabilities of the “El Capitan” supercomputer being built right now at Lawrence Livermore National Laboratory by Hewlett Packard Enterprise in conjunction with compute engine supplier AMD. We need to know because we want to understand the very different – and yet, in some ways similar – architectural path that China seems to have taken with the Xingyi architecture to break through the exascale barrier.
Just because the details of these machines in their fullest configurations have not been disclosed by the Chinese government does not mean they do not loom large over the upper echelons of supercomputing.
That is why in our analysis of the Top500 supercomputer rankings back in November, we reminded everyone that based on the rumored performance of Xingyi at NSC Guangzhou – 2.05 exaflops peak and 1.57 exaflops sustained on High Performance LINPACK – that it was the most powerful machine yet assembled on Earth. And we also reminded everyone that the Oceanlight system at NSC Wuxi was the second most powerful machine on the planet, with 1.5 exaflops peak and around 1.22 exaflops sustained on LINPACK. So this is how the actual Top30 supercomputer rankings in November might have looked had China submitted results:
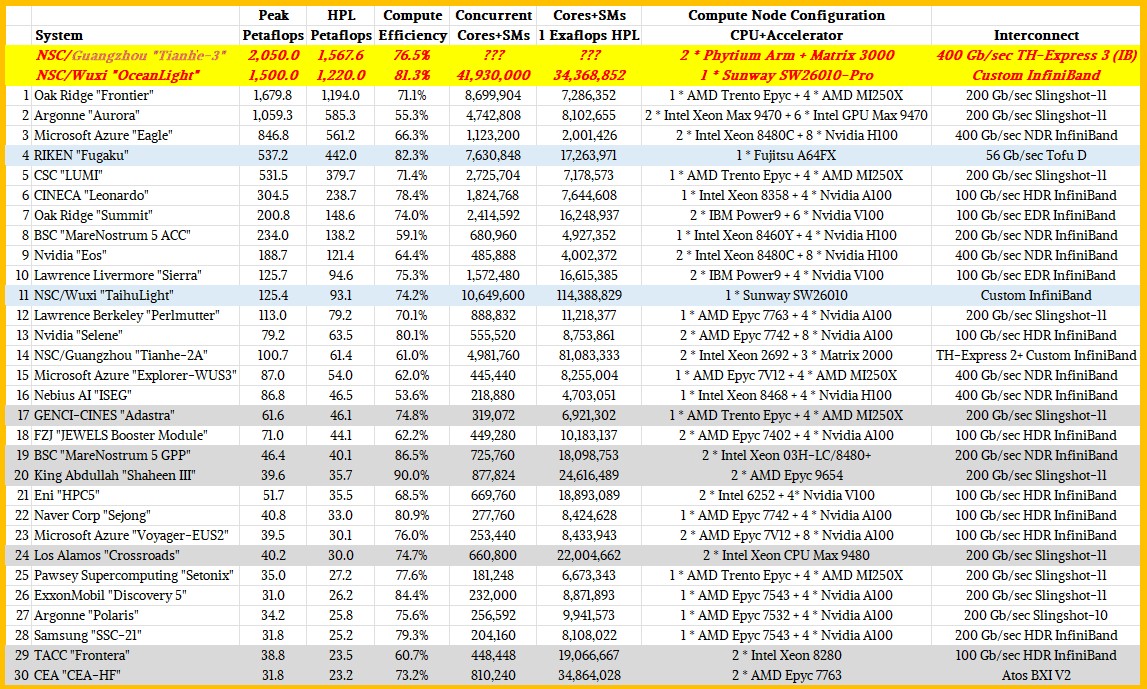
We think there is a very good chance that El Capitan will come in at 2.3 exaflops peak when it is fully fired up, hopefully by the June 2024 rankings. You can bet Elon Musk’s last dollar that the premiere supercomputing lab in the United States will be getting all the help it needs to beat what we think the two Chinese machines can do.
An Evolutionary Approach
There have been five Tianhe machines built in China (six if you count the Tianhe-3 prototype), all of them designed and constructed by the National University of Defense Technology. (Tianhe is Chinese for “Sky River” and refers to what we in North American and Europe call “Milky Way” after the edge of our galaxy that we can see spanning the night sky.) And as you can see, the third machine, Tianhe-2A, is still powerful enough to make the Top30 rankings of real supercomputers even after being in the field for a long time.Tianhe-1 was revealed in October 2009, and was ranked fifth on the Top500 list that fall. Tianhe-1 had a hybrid CPU-GPU architecture, which was just starting to become more commonplace at the time, and used 5,120 Intel Xeon E5 processors that were paired 1:1 with 5,120 AMD GPU. There were 2,560 two-socket Xeons server nodes with an equal number of dual Radeon 4870 X2 cards. This machine had 1.2 petaflops peak and 563 teraflops of LINPACK oomph. This machine was installed at the National Supercomputer Center in Tianjin, China. (Which is why our original Top500 chart back in November placed Tianhe-3 there incorrectly.)
A year later, the Tianhe-1A machine was launched, and not only did it have lot more 64-bit floating point oomph and a different architecture, it was the highest performing machine that China had ever built. This machine had 7,168 two-socket Xeon X5670 server nodes, each one with an Nvidia M2050 GPU. There were an additional 2,048 FeiTeng 1000 Sparc T5 clones – the T5 design was open sourced by Sun Microsystems – that were part of the Tianhe-1A system, but they did not underpin the LINPACK results. This system had 4.7 petaflops of peak performance and 2.57 petaflops sustained on LINPACK, and really marked the rise of China in HPC. Tianhe-1A was noteworthy in that it also included a proprietary interconnect code-named Arch that ran at 160 Gb/sec and that we still believe, based on rumors, was an overclocked or enfattened variation of QDR InfiniBand. This interconnect has evolved and is now called TH-Express as far as we know.
At the time, there was talk that the next-generation Tianhe machine would be based on the homegrown Loongson MIPS architecture and would be designed and built by upstart Chinese server maker Dawning. But that didn’t happen.
With the Tianhe-2 machine, NUDT was able to get the machine into the field two years early and moved the family of hybrid supercomputers to NSC Guangzhou in the southern part of China for reasons that have never been explained but were probably political in nature. One reason it could be fast is that it was based on Intel Xeon CPU and “Knights” Xeon Phi manycore accelerators. To be precise, Tianhe-2 had 16,000 nodes, each with a pair of Xeon E5-2692 processors and four Xeon Phi 31S1P accelerators. It cost around $390 million to build, and was twice as fast as the “Titan” supercomputer at Oak Ridge National Laboratory when it came online in 2013. Tianhe-2 was rated at 54.9 petaflops peak and 33.9 petaflops sustained on LINPACK, a 62 percent computational efficiency that was a lot better than the 47 percent that NUDT got with the Tianhe-1A system. Tianhe-2 did burn 17 megawatts, though....
....MUCH MORE